
RDM Weekly - Issue 021
A weekly roundup of Research Data Management resources.


Welcome to Issue 21 of the RDM Weekly Newsletter!
The content of this newsletter is divided into 3 categories:
✅ What’s New in RDM?
These are resources that have come out within the last year or so
✅ Oldies but Goodies
These are resources that came out over a year ago but continue to be excellent ones to refer to as needed
✅ Just for Fun
A data management meme or other funny data management content
What’s New in RDM?
Resources from the past year
1. Data Documentation and Validation using R
Research data without proper documentation becomes a barrier to reproducibility and collaboration. This tutorial from LMU Open Science Center teaches you to document, summarize, and validate your research data using R, focusing on practical skills that make your work more transparent and reusable. By the end of the tutorial you will be able to create data dictionaries, use summary statistics, implement automated validation, and generate professional reports.
2. Designing a Survey Part 1 - Asking Good Questions
When designing a survey, crafting good questions isn’t as easy as writing down what you want to know. You are likely managing competing interests from your board, funders, team, and community. Perhaps you feel pressured to measure things that will result in glowing reviews. Or, you might find yourself handcuffed to survey software that is less than ideal. Limited resources, time crunches, and pressure often result in questions that are clunky, confusing, and burdensome for participants. The result? Participants skip through questions or abandon the survey. The survey falls apart when questions aren’t answerable. The authors of this blog post provide 5 of the most common mistakes they see folks make when crafting questions - and they provide solutions on how to fix them before your survey goes live.
3. Research Data Management Framework Policy - TU/e
This research data management policy from Eindhoven University of Technology (TU/e) is another great example of how institutions can provide an overarching framework on how to manage research data (see Issue 004 of RDM Weekly for another example from Utrecht University). The TU/e Research Data Framework Policy supports the development of professional practices and policies for research data management across each of the departments at TU/e and it provides clear roles and responsibilities for researchers and research support staff regarding the management of research data.
4. Licensing Your Research Data
Part of a larger Research Data Management Guide from UBC Library Research Commons, the authors most recently added this section on Licensing Your Research Data. Using a license is a good way of communicating permission to potential users on how your work can be used. It ensures you’re getting the proper credit for your work when sharing it. However, there are many types of licenses for various kinds of products, contexts, and disciplines. Each has its own unique purpose, policies, and legal protection. Choosing the best license depends on your preferences and the nature of your work. This section, as well as the accompanying one-pager, are great resources to help you think through your options.
5. FAIR-SMART Expands Access to Supplementary Materials for Research Transparency
Supplementary materials accompanying scientific articles are critical components of biomedical research, offering detailed datasets, experimental protocols, and extended analyses that complement the main text. These materials play an important role in enhancing transparency, reproducibility, and scientific impact by providing in depth analyses and the details necessary for reproducing experiments. However, the lack of consistent and standard formats has limited the access to supplementary materials in scientific investigations. In response, the authors of this paper propose a novel system aimed to enhance FAIR access to Supplementary MAterials for Research Transparency (FAIR-SMART). Specifically, they first aggregate supplementary files in a single location, standardize them into a structured and machine-readable format, and make them accessible via web APIs. Next, they employ advanced large language models to automatically categorize the tabular data, which represents over 90% of the textual content in supplementary materials, enabling precise and efficient data retrieval. By bridging the gap between diverse file types and automated workflows, this work not only advances biomedical research but also highlights the transformative potential of accessible supplementary materials in shaping the behaviors and decision-making processes of the scientific community.
6. Obstacles to Dataset Citation Using Bibliographic Management Software
Governmental, funder, and scholarly publisher mandates for FAIR and open data are pushing researchers to archive data with persistent identifiers in repositories and link datasets in journal articles. Data citations enable transparency in research and credit and impact metrics for data reuse. However, numerous adoption barriers still exist, including that bibliographic reference management software commonly used by researchers to ease the referencing process may not yet be equipped to handle datasets. This paper examines the readiness of commonly used reference management software to support researchers in importing bibliographic metadata for datasets and generating references that comply with leading practices for data citation. The authors find that a majority of frequently used reference managers do not adequately support data citation, obstructing uptake of data citation by researchers and thereby limiting the growth of credit and incentives for data sharing and reuse. The range and scale of issues uncovered are broadly extensible and relevant to data citation across disciplines. The authors present actionable recommendations for reference manager, data repository, scholarly publisher, and researcher stakeholders for increasing the ease, efficiency, and accuracy of bibliographic management software-facilitated data citation.
7. Request for Data from Reading Intervention Studies
The NIH-funded IDARE (Integrating Data to Advance Reading Evidence) Project team welcomes contributions for this open science project. The project is focused on integrating existing deidentified datasets from reading intervention studies, specifically experimental studies of K-12 supplemental reading interventions (Tier 2 or 3), to investigate potential sources of individual difference in intervention effects. If you would like to contribute data to this project, you can complete the interest form. The IDARE integrated dataset will be archived in the LDbase data repository and will generate new knowledge to advance reading research. If you share data, the IDARE team will support the review of your files and logistics of transferring data. They will also create a project page for you in LDbase, which you control and determine level of access you wish to allow in the future.
Oldies but Goodies
Older resources that are still helpful
1. Library Carpentry: Introduction to Regular Expressions
This tool-agnostic Library Carpentry lesson introduces people with library- and information-related roles to working with regular expressions. The lesson provides background on the regular expression language and how it can be used to match and extract text and to clean data.
2. Project Structure - Slides
These slides from Danielle Navarro cover two things very well, naming files and structuring projects. The slides review concepts such as naming files so that they are both human and machine readable, and in a way that allows files to be searched and sorted. Last they cover how to organize those files in a clear and usable folder structure.
3. AI TutoR
This open access book, started in Spring 2024, continues to be updated and should be considered a living document. The book aims to teach students how to use AI to support their learning journey. The philosophy of this book is firmly rooted in the cognitive science of learning and as such, retrieval practice, distributed practice, and elaboration all play a key role. The book is intended to be used alongside other course materials that contain intended learning outcomes and key terms. The book aims to help learners use AI platforms critically and among other outcomes, by the end of the book learners should be able to use AI as a pair programmer to debug errors in code, to review, comment, and refactor code, and to responsibly assist with writing code. Learners should also be able to critically evaluate and appraise the output of AI.
4. Asymptotics of Reproducibility
In this 2020 blog post, Roger Peng discusses reproducibility value. He suggests that reproducibility of scientific research is of critical importance, perhaps now more than ever. However, we need to think harder about how we can support it in both the short- and long-term. Just assuming that the maintenance and support costs of reproducibility for every study are merely nominal is not realistic and simply leads to investigators not supporting reproducibility as a default.
Just for Fun
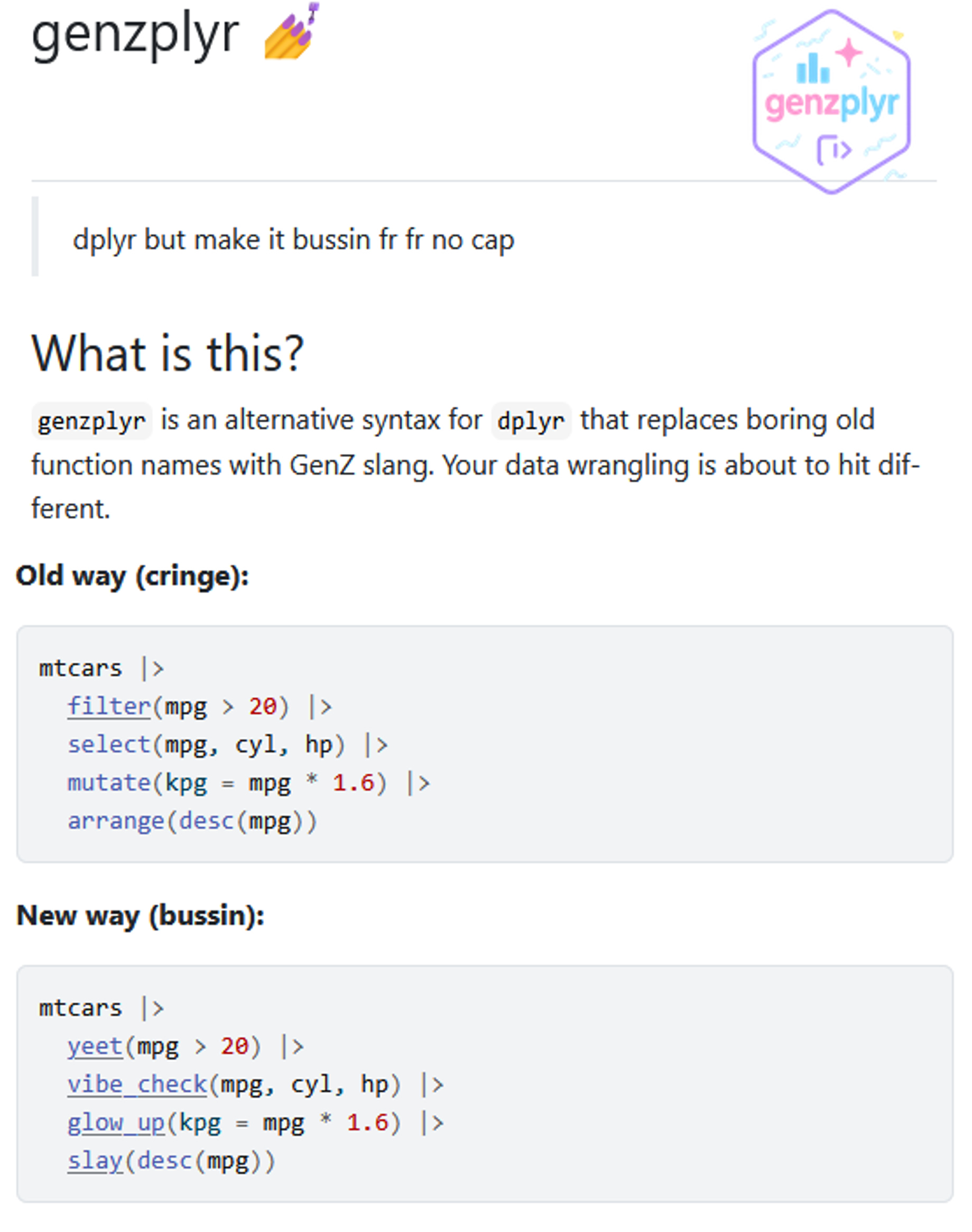
Thank you for checking out the RDM Weekly Newsletter! If you enjoy this content, please like, comment, or share this post! You can also support this work through Buy Me A Coffee.